NPU와 GPU, 온디바이스 AI의 핵심, 차이점 알아보기
스마트폰 온디바이스 AI의 핵심인 NPU와 GPU의 구조적 차이점과 효율성을 분석하여, 내 기기의 AI 성능을 결정짓는 진정한 유닛이 무엇인지 상세히 살펴본다.
최근 출시되는 스마트폰의 상세 스펙을 살펴보면 'AI 성능'이라는 단어가 빠지지 않고 등장한다. 불과 몇 년 전만 해도 우리는 CPU와 GPU의 클럭 속도에만 열광했지만, 이제는 'NPU'라는 생소한 유닛의 성능이 스마트폰의 급을 나누는 척도가 되었다. 갤럭시의 실시간 통역이나 아이폰의 지능형 사진 편집 기능이 클라우드를 거치지 않고 내 손안에서 즉시 실행되는 '온디바이스 AI' 시대가 열리면서, 데이터를 처리하는 뇌의 구조 자체가 변하고 있는 것이다. 과연 우리가 매일 사용하는 이 작은 기기 속에서 어떤 일이 벌어지고 있는지, 그리고 왜 기존의 강력한 GPU만으로는 부족했는지에 대해 깊이 고민해 보게 된다. 단순히 숫자 놀음에 불과한 스펙 경쟁이 아니라, 우리의 디지털 경험을 근본적으로 바꾸는 이 기술적 차이를 이해하는 것은 꽤나 흥미로운 일이다.
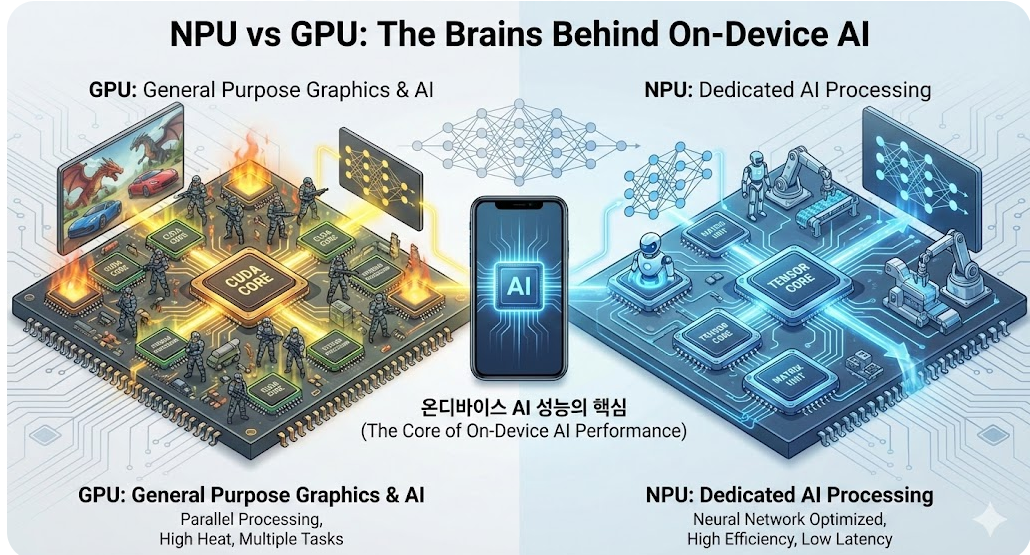
그래픽을 그리던 병사들과 AI만을 위해 태어난 전문가의 차이
우리가 흔히 알고 있는 GPU는 원래 그래픽 처리를 위해 탄생한 유닛이다. 수만 개의 픽셀을 동시에 계산하여 화면에 뿌려줘야 하기에, GPU는 수많은 단순 연산 장치(Core)를 병렬로 배치한 구조를 가진다. 이 방식은 딥러닝의 핵심 연산인 행렬 곱셈과도 어느 정도 결이 맞아서 초기 AI 발전의 일등 공신 역할을 했다. 하지만 나는 GPU가 AI 전담 부서라기보다는 '범용적인 병렬 처리 부대'에 가깝다고 생각한다. 그래픽 렌더링도 해야 하고, 복잡한 쉐이더 계산도 수행해야 하는 GPU에게 오로지 AI 연산만을 맡기기에는 구조적인 낭비가 존재할 수밖에 없기 때문이다. 게임을 돌리면서 동시에 고성능 AI 기능을 수행할 때 스마트폰이 뜨거워지는 이유도 결국 GPU가 너무 많은 짐을 짊어지고 있기 때문이 아닐까 싶다.
반면 NPU는 오직 인간의 뇌 신경망을 모사한 알고리즘을 처리하기 위해 설계된 특수 목적 유닛이다. GPU가 수천 명의 일반 병사라면, NPU는 특정 작업을 위해 고도로 훈련된 소수의 정예 요원 혹은 자동화된 전용 생산 라인과 같다. AI 모델이 요구하는 방대한 양의 데이터를 가장 적은 동선으로 처리할 수 있도록 데이터 통로 자체를 최적화해 둔 것이다. 나는 개인적으로 이 차이를 '범용 도구'와 '전용 키트'의 차이라고 생각한다. 맥가이버 칼이 아무리 유용해도 전문 목수의 정교한 조각 칼을 이길 수 없듯이, 딥러닝 연산에 최적화된 NPU는 GPU보다 훨씬 적은 자원으로 더 빠르게 결과값을 도출해낸다. 실제로 최신 프로세서에서 NPU의 비중이 높아질수록 사진의 노이즈 제거 속도가 비약적으로 빨라지는 것을 보며, 설계의 목적이 성능을 얼마나 극적으로 가르는지 새삼 느끼게 된다.

온디바이스 AI의 생존 전략인 전력 효율과 지연 시간의 극복
스마트폰에서 성능만큼 중요한 것이 바로 배터리 효율이다. 아무리 똑똑한 AI 기능을 갖추고 있어도 기능을 한 번 쓸 때마다 배터리가 눈에 띄게 줄어든다면 그것은 실용적인 기술이라고 보기 어렵다. 여기서 NPU의 진가가 드러난다. GPU는 구조상 AI 연산을 수행할 때 데이터가 메모리와 연산 장치를 빈번하게 오가야 하므로 전력 소모가 상당하다. 하지만 NPU는 데이터를 효율적으로 재사용하고 이동 경로를 최소화하는 설계를 통해, 동일한 AI 작업을 수행할 때 GPU 대비 수십 배 이상의 전력 효율을 보여주기도 한다. 나는 이러한 효율성이야말로 온디바이스 AI가 대중화될 수 있었던 결정적인 열쇠라고 본다. 전력 효율이 담보되지 않았다면 우리는 아마 지금도 모든 AI 연산을 거대한 서버가 있는 클라우드에 맡기고, 느린 응답 속도를 인내하며 살고 있었을지도 모른다.
또한 지연 시간, 즉 '레이턴시'의 측면에서도 NPU의 존재감은 독보적이다. 실시간 통역이나 카메라 프리뷰에서 즉각적으로 피사체를 인식하는 기능은 0.1초의 차이로 사용자 경험이 완전히 갈린다. GPU가 다른 그래픽 작업과 자원을 공유하며 연산 순서를 기다리는 동안, NPU는 독립된 전용 통로를 통해 즉각적으로 데이터를 처리한다. 최근 스마트폰으로 사진을 찍을 때 셔터를 누르기도 전에 이미 최적화된 결과물을 보여주는 '제로 셔터 랙' 기반의 AI 보정 기능을 보며, 이것이 하드웨어적 뒷받침 없이는 불가능한 영역이라는 확신이 들었다. 단순히 소프트웨어가 좋아진 것이 아니라, 그 소프트웨어를 가장 빠르게 돌릴 수 있는 '전용 엔진'인 NPU가 우리 손안에 들어왔기 때문에 가능한 일이다.

하드웨어의 한계를 넘어 개인화된 비서로 진화하는 모바일 AP
결국 NPU와 GPU는 서로를 배척하는 존재가 아니라 보완하며 공진화하는 관계에 있다. 최신 모바일 AP(Application Processor)에서는 CPU, GPU, NPU가 하나의 유기체처럼 움직이며 작업의 성격에 따라 역할을 분담한다. 화면의 UI를 부드럽게 넘기는 것은 CPU가, 화려한 게임 그래픽은 GPU가, 그리고 사용자의 패턴을 학습하고 사진을 예술적으로 다듬는 일은 NPU가 맡는 식이다. 나는 앞으로 스마트폰의 경쟁력이 단순히 '얼마나 빠른가'에서 '얼마나 나를 잘 이해하는가'로 옮겨갈 것이라고 본다. 그리고 그 이해의 깊이를 결정짓는 것이 바로 NPU의 연산 능력인 'TOPS(Tera Operations Per Second)' 수치가 될 것이다. 숫자가 높을수록 더 복잡한 거대 언어 모델(LLM)을 내 폰에서 직접 구동할 수 있게 되기 때문이다.
이러한 변화를 지켜보며 문득 우리가 가진 기기가 단순한 통신 수단을 넘어 하나의 독립된 지능체로 변모하고 있다는 생각이 든다. 예전에는 사진 한 장을 보정하기 위해 전문가용 PC 앞에 앉아야 했지만, 이제는 주머니 속 NPU가 실시간으로 수억 번의 계산을 수행하며 최상의 결과물을 만들어낸다. 그것은 기술의 승리이기도 하지만, 한편으로는 인간의 창의성을 보조하는 도구가 극도로 개인화되고 있음을 의미한다. NPU 성능이 비약적으로 발전함에 따라, 머지않아 네트워크 연결 없이도 나만의 맞춤형 비서가 모든 일정을 관리하고 완벽한 문장을 초안으로 잡아주는 시대가 올 것이다. 그 시작점에 바로 지금 우리가 논의하는 이 작은 반도체 유닛들의 차이가 있다고 확신한다.

요약하자면, GPU는 병렬 처리에 능한 범용 그래픽 유닛으로 AI 초창기에 큰 역할을 했으나 전력 효율 면에서 한계가 있다. 반면 NPU는 AI 연산만을 위해 설계된 전용 유닛으로, 압도적인 전력 효율과 빠른 처리 속도를 통해 온디바이스 AI를 가능케 한다. 스마트폰의 성능을 단순히 벤치마크 점수로만 보지 말고, 실질적인 AI 경험을 뒷받침하는 NPU의 발전에 주목해야 하는 이유다.